
Automatically validated tabular data

One-off validation of your tabular datasets can be hectic, especially where plenty of published data is maintained and updated fairly regularly.
Running continuous checks on data provides regular feedback and contributes to better data quality as errors can be flagged and fixed early on. This section introduces you to tools that continually check your data for errors and flag content and structural issues as they arise. By eliminating the need to run manual checks on tabular datasets every time they are updated, they make your data workflow more efficient.
In this section, you will learn how to setup automatic tabular data validation using goodtables, so your data is validated every time it’s updated. Although not strictly necessary, it’s useful to know about Data Packages and Table Schema before proceeding, as they allow you to describe your data in more detail, allowing more advanced validations.
We will show how to set up automated tabular data validations for data published on:
- CKAN (opens new window), an open source data publishing platform;
- GitHub (opens new window), a hosting service;
- Amazon S3 (opens new window), a data storage service.
If you don’t use any of these platforms, you can still setup the validation using goodtables-py (opens new window), it will just require some technical knowledge
If you do use some of these platforms, the data validation report look like:
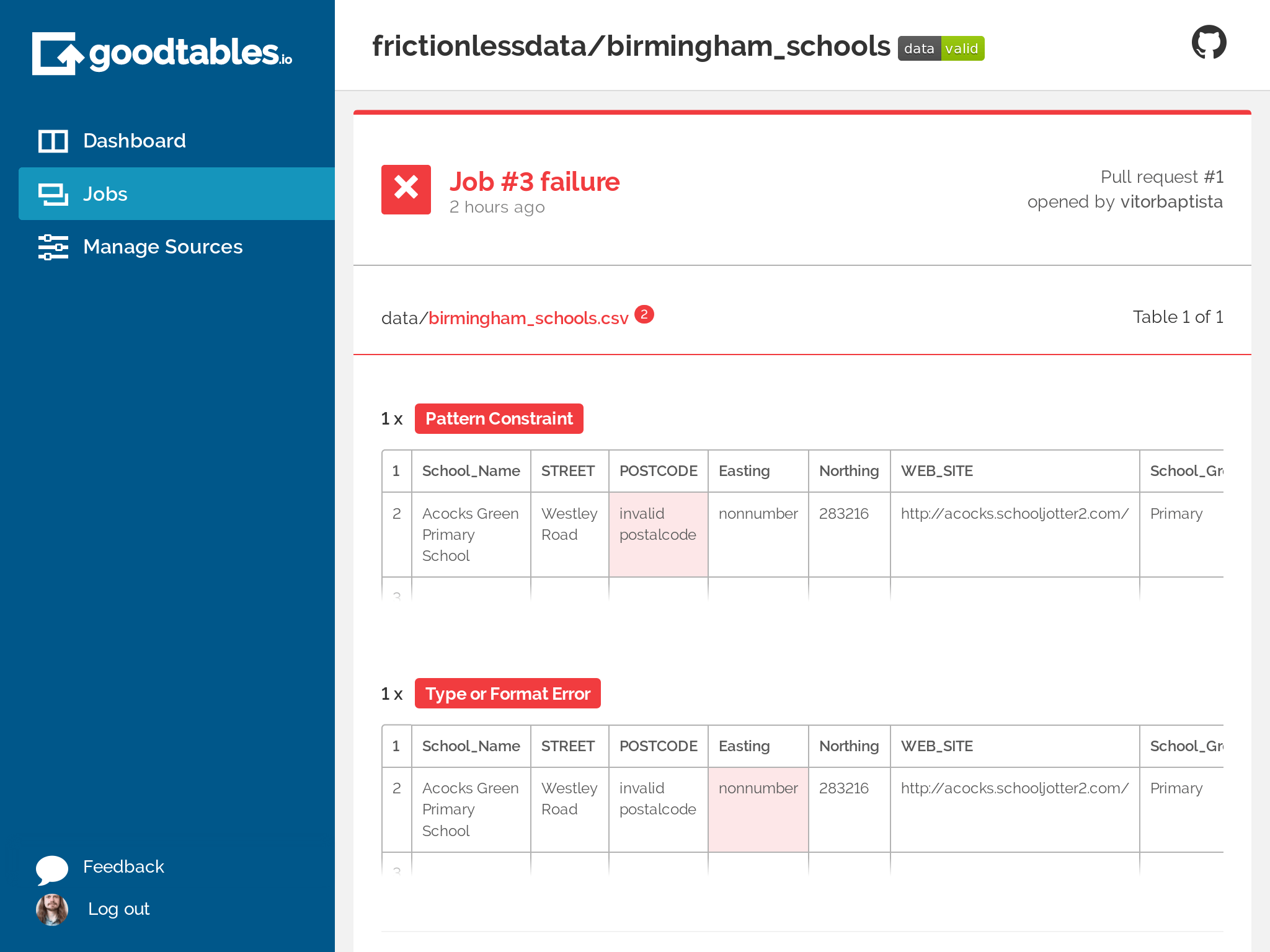 (opens new window)
(opens new window)
Figure 1: Goodtables.io (opens new window) tabular data validation report.
# Validate tabular data automatically on CKAN
CKAN (opens new window) is an open source platform for publishing data online. It is widely used across the planet, including by the federal governments of the USA, United Kingdom, Brazil, and others.
To automatically validate tabular data on CKAN, enable the ckanext-validation (opens new window) extension, which uses goodtables to run continuous checks on your data. The ckanext-validation (opens new window) extension:
- Adds a badge next to each dataset showing the status of their validation (valid or invalid), and
- Allows users to access the validation report, making it possible for errors to be identified and fixed.
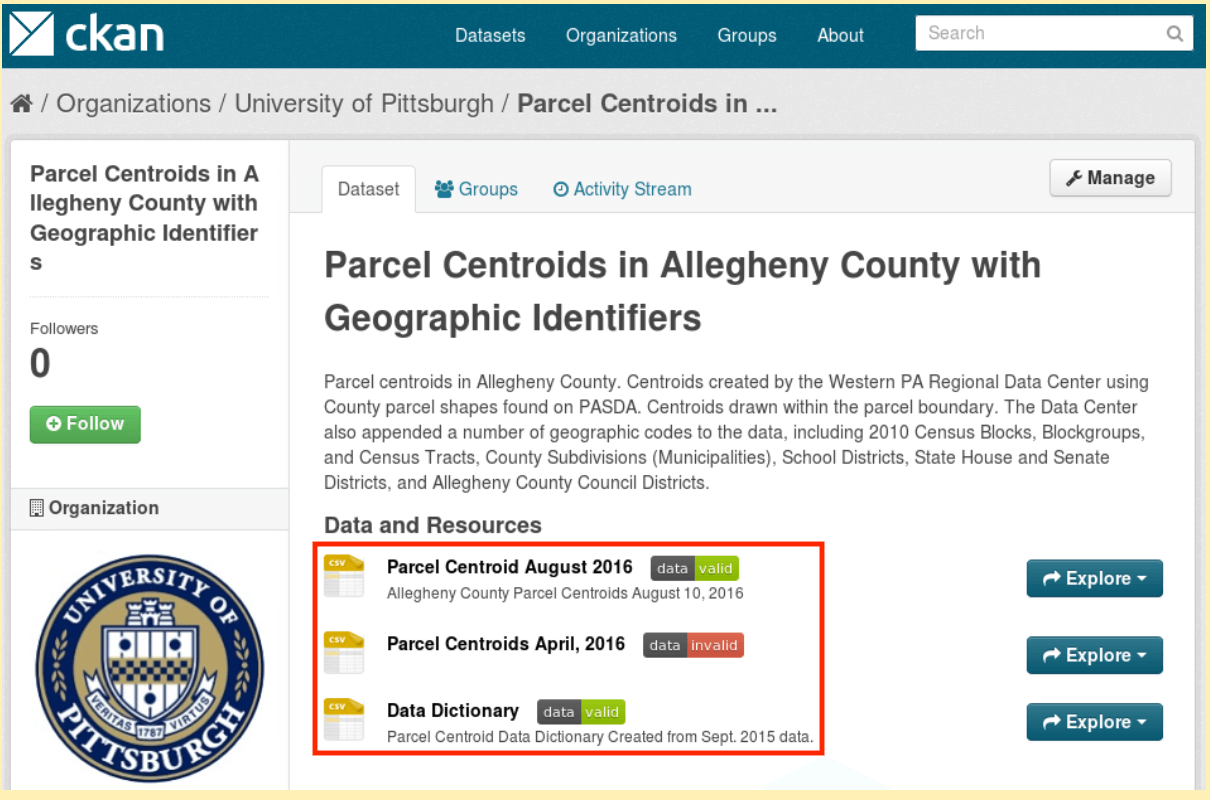
Figure 2: Annotated in red, automated validation checks on datasets in CKAN.
The installation and usage instructions for ckanext-validation (opens new window) extension are available on Github (opens new window).
# Validate tabular data automatically on GitHub
If your data is hosted on GitHub, you can use goodtables web service to automatically validate it on every change.
For this section, you will first need to create a GitHub repository (opens new window) and add tabular data to it.
Once you have tabular data in your Github repository:
- Login on goodtables.io (opens new window) using your GitHub account and accept the permissions confirmation.
- Once we’ve synchronized your repository list, go to the Manage Sources (opens new window) page and enable the repository with the data you want to validate.
- If you can’t find the repository, try clicking on the Refresh button on the Manage Sources page
Goodtables will then validate all tabular data files (CSV, XLS, XLSX, ODS) and data packages (opens new window) in the repository. These validations will be executed on every change, including pull requests.
# Validate tabular data automatically on Amazon S3
If your data is hosted on Amazon S3, you can use goodtables.io (opens new window) to automatically validate it on every change.
It is a technical process to set up, as you need to know how to configure your Amazon S3 bucket. However, once it’s configured, the validations happen automatically on any tabular data created or updated. Find the detailed instructions here (opens new window).
# Custom setup of automatic tabular data validation
If you don’t use any of the officially supported data publishing platforms, you can use goodtables-py (opens new window) directly to validate your data. This is the most flexible option, as you can configure exactly when, and how your tabular data is validated. For example, if your data come from an external source, you could validate it once before you process it (so you catch errors in the source data), and once after cleaning, just before you publish it, so you catch errors introduced by your data processing.
The instructions on how to do this are technical, and can be found on https://github.com/frictionlessdata/goodtables-py (opens new window).