
# Frictionless Data
Get a quick introduction to Frictionless in “5 minutes”.
Frictionless Data is a progressive open-source framework for building data infrastructure – data management, data integration, data flows, etc. It includes various data standards and provides software to work with data.
TIP
This introduction assumes some basic knowledge about data. If you are new to working with data we recommend starting with the first module, “What is Data?”, at School of Data (opens new window).
# Why Frictionless?
The Frictionless Data project aims to make it easier to work with data - by reducing common data workflow issues (what we call friction). Frictionless Data consists of two main parts, software and standards.
# Frictionless Software
The software is based on a suite of data standards that have been designed to make it easy to describe data structure and content so that data is more interoperable, easier to understand, and quicker to use. There are several aspects to the Frictionless software, including two high-level data frameworks (for Python and JavaScript), 10 low-level libraries for other languages, like R, and also visual interfaces and applications. You can read more about how to use the software (and find documentation) on the projects page.
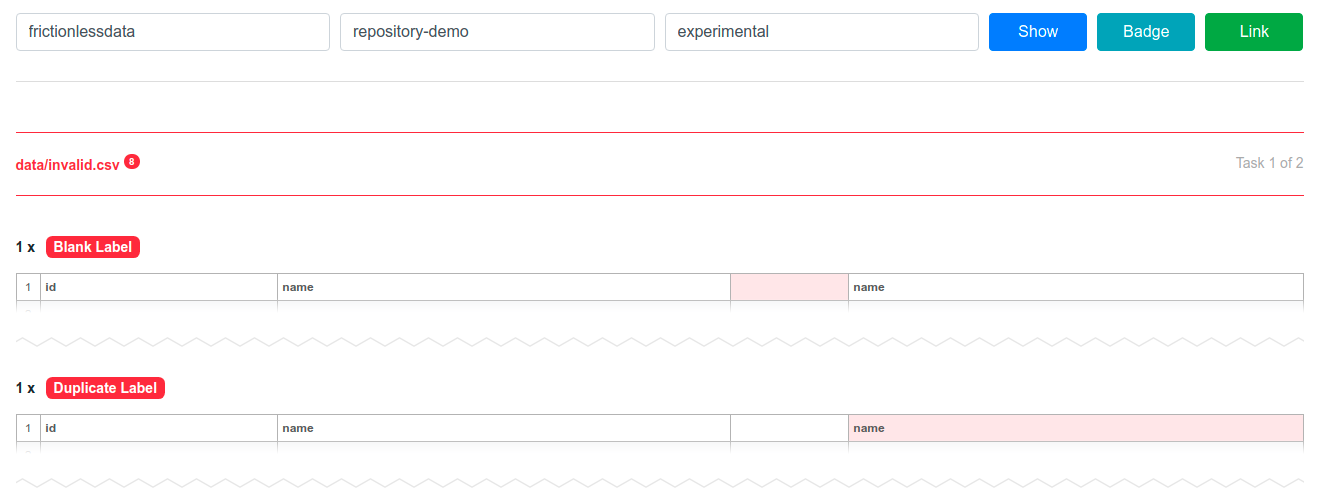
For example, here is a validation report created by the Frictionless Repository (opens new window) software. Data validation is one of the main focuses of Frictionless Data and this is a good visual representation of how the project might help to reveal common problems working with data.
# Frictionless Standards
The Standards (aka Specifications) help to describe data. The core specification is called a Data Package, which is a simple container format used to describe and package a collection of data files. The format provides a contract for data interoperability that supports frictionless delivery, installation and management of data.
A Data Package can contain any kind of data. At the same time, Data Packages can be specialized and enriched for specific types of data so there are, for example, Tabular Data Packages for tabular data, Geo Data Packages for geo data, etc.
To learn more about Data Packages and the other specifications, check out the projects page or watch this video to learn more about the motivation behind packaging data.
# How can I use Frictionless?
You can use Frictionless to describe your data (add metadata and schemas), validate your data, and transform your data. You can also write custom data standards based on the Frictionless specifications. For example, you can use Frictionless to:
- easily add metadata to your data before you publish it.
- quickly validate your data to check the data quality before you share it.
- build a declarative pipeline to clean and process data before analyzing it.
Usually, new users start by trying out the software. The software gives you an ability to work with Frictionless using visual interfaces or programming languages.
As a new user you might not need to dive too deeply into the standards as our software incapsulates its concepts. On the other hand, once you feel comfortable with Frictionless Software you might start reading Frictionless Standards to get a better understanding of the things happening under the hood or to start creating your metadata descriptors more proficiently.
# Who uses Frictionless?
The Frictionless Data project has a very diverse audience, ranging from climate scientists, to humanities researchers, to government data centers.
During our project development we have had various collaborations with institutions and individuals. We keep track of our Pilots and Case Studies with blog posts, and we welcome our community to share their experiences using our standards and software. Generally speaking, you can apply Frictionless in almost every field where you work with data. Your Frictionless use case could range from a simple data table validation to writing complex data pipelines.
# Ready for more?
As a next step, we recommend you start using one of our Software projects, get known our Standards or read about other user experience in Pilots and Case Studies sections. Also, we welcome you to reach out on Slack (opens new window) or Matrix (opens new window) to say hi or ask questions!