Data Software and Standards
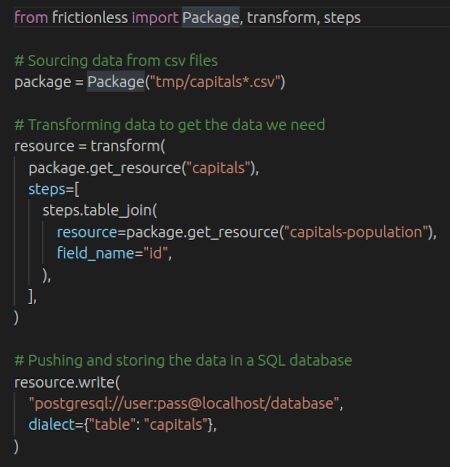
Frictionless is an open-source toolkit that brings simplicity to the data experience - whether you're wrangling a CSV or engineering complex pipelines.

Approachable
A lean and minimal core. Quick to understand, quick to use.
Incrementally Adoptable
Start with just what you need, scale as you grow.
Progressive
Enhance, rather than replace, your existing tools and workflows.