
Western Pennsylvania Regional Data Center

# Context
One of the main goals of the Frictionless Data project is to help improve data quality by providing easy to integrate libraries and services for data validation. We have integrated data validation seamlessly with different backends like GitHub and Amazon S3 via the online service goodtables.io (opens new window), but we also wanted to explore closer integrations with other platforms.
An obvious choice for that are Open Data portals. They are still one of the main forms of dissemination of Open Data, especially for governments and other organizations. They provide a single entry point to data relating to a particular region or thematic area and provide users with tools to discover and access different datasets. On the backend, publishers also have tools available for the validation and publication of datasets.
Data Quality varies widely across different portals, reflecting the publication processes and requirements of the hosting organizations. In general, it is difficult for users to assess the quality of the data and there is a lack of descriptors for the actual data fields. At the publisher level, while strong emphasis has been put in metadata standards and interoperability, publishers don’t generally have the same help or guidance when dealing with data quality or description.
We believe that data quality in Open Data portals can have a central place on both these fronts, user-centric and publisher-centric, and we started this pilot to showcase a possible implementation.
To field test our implementation we chose the Western Pennsylvania Regional Data Center (opens new window) (WPRDC), managed by the University of Pittsburgh Center for Urban and Social Research (opens new window). The Regional Data Center made for a good pilot as the project team takes an agile approach to managing their own CKAN instance along with support from OpenGov, members of the CKAN association. As the open data repository is used by a diverse array of data publishers (including project partners Allegheny County and the City of Pittsburgh), the Regional Data Center provides a good test case for testing the implementation across a variety of data types and publishing processes. WPRDC is a great example of a well managed Open Data portal, where datasets are actively maintained and the portal itself is just one component of a wider Open Data strategy. It also provides a good variety of publishers, including public sector agencies, academic institutions, and nonprofit organizations. The project’s partnership with the Digital Scholarship Services team at the University Library System also provides data management expertise not typically available in many open data implementations.
# The Work
# What Did We Do
The portal software that we chose for this pilot is CKAN (opens new window), the world’s leading open source software for Open Data portals (source (opens new window)). Open Knowledge International initially fostered the CKAN project and is now a member of the CKAN Association (opens new window).
We created ckanext-validation (opens new window), a CKAN extension that provides a low level API and readily available features for data validation and reporting that can be added to any CKAN instance. This is powered by goodtables (opens new window), a library developed by Open Knowledge International to support the validation of tabular datasets.
The extension allows users to perform data validation against any tabular resource, such as CSV or Excel files. This generates a report that is stored against a particular resource, describing issues found with the data, both at the structural level (missing headers, blank rows, etc) and at the data schema level (wrong data types, values out of range etc).
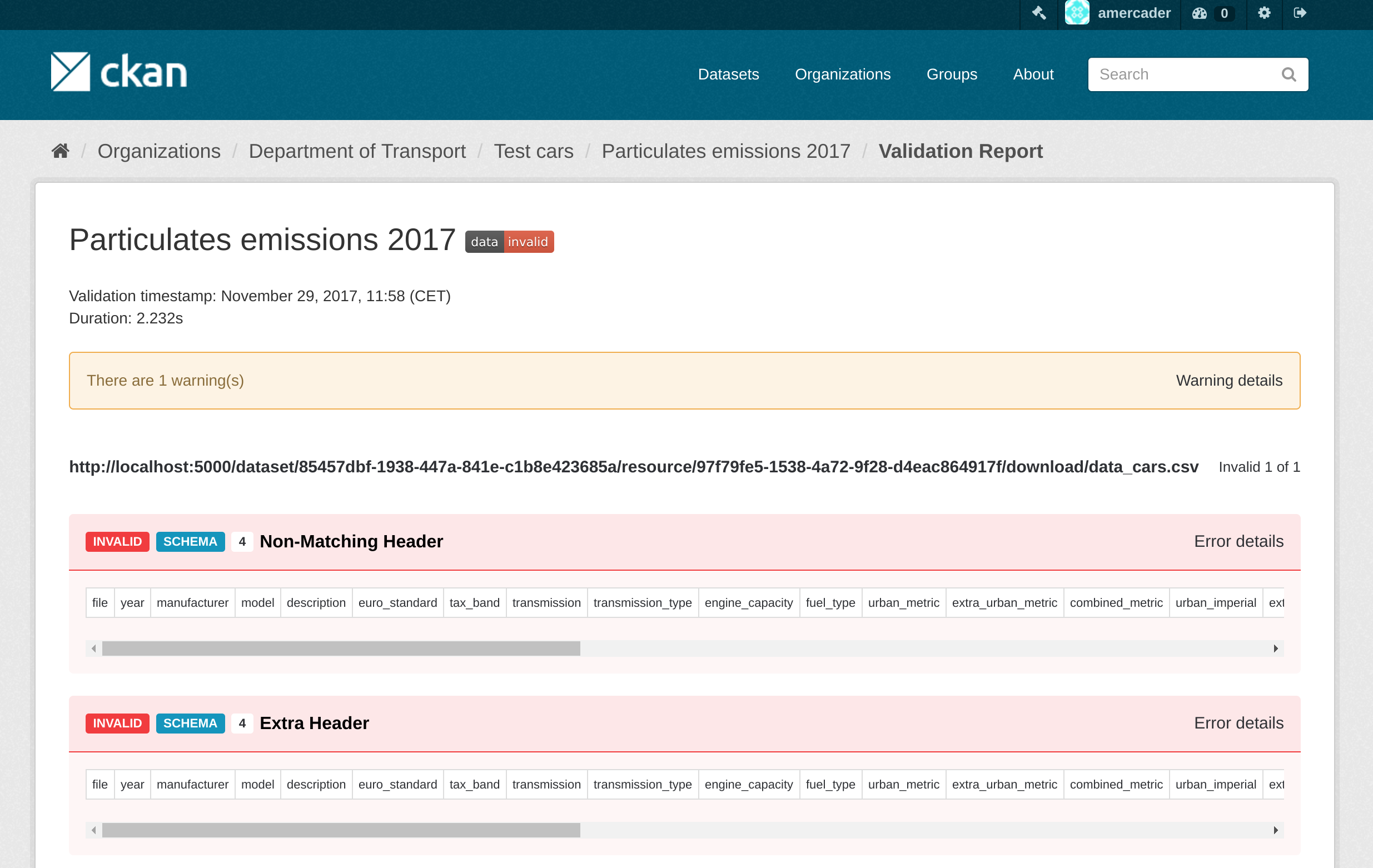
data validation on CKAN made possible by ckanext-validation extension
This provides a good overview of the quality of the data to users but also to publishers so they can improve the quality of the data file by addressing these issues. The reports can be easily accessed via badges that provide a quick visual indication of the quality of the data file.
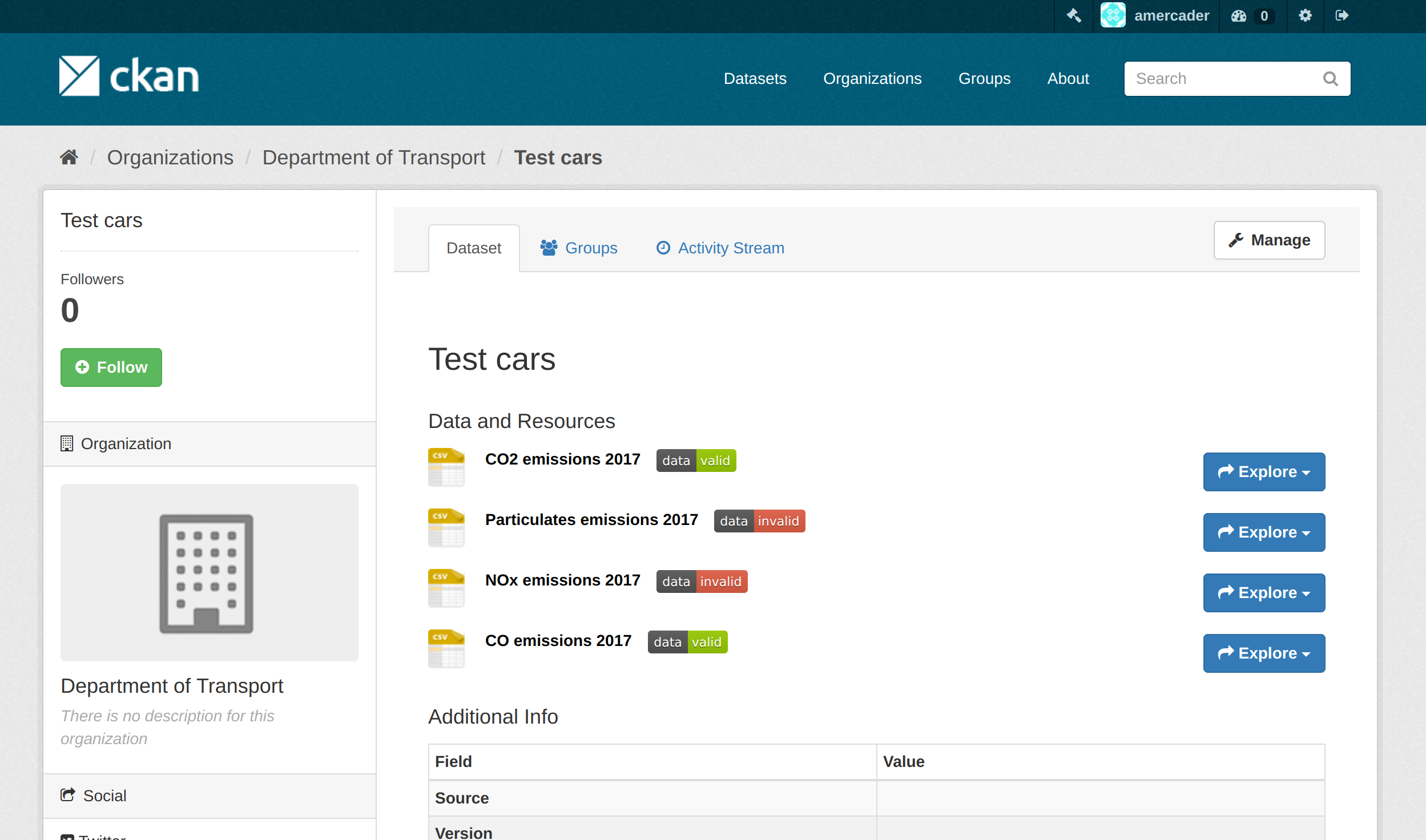
badges indicating quality of data files on CKAN
There are two default modes for performing the data validation when creating or updating resources. Data validation can be automatically performed in the background asynchronously or as part of the dataset creation in the user interface. In this case the validation will be performed immediately after uploading or linking to a new tabular file, giving quick feedback to publishers.
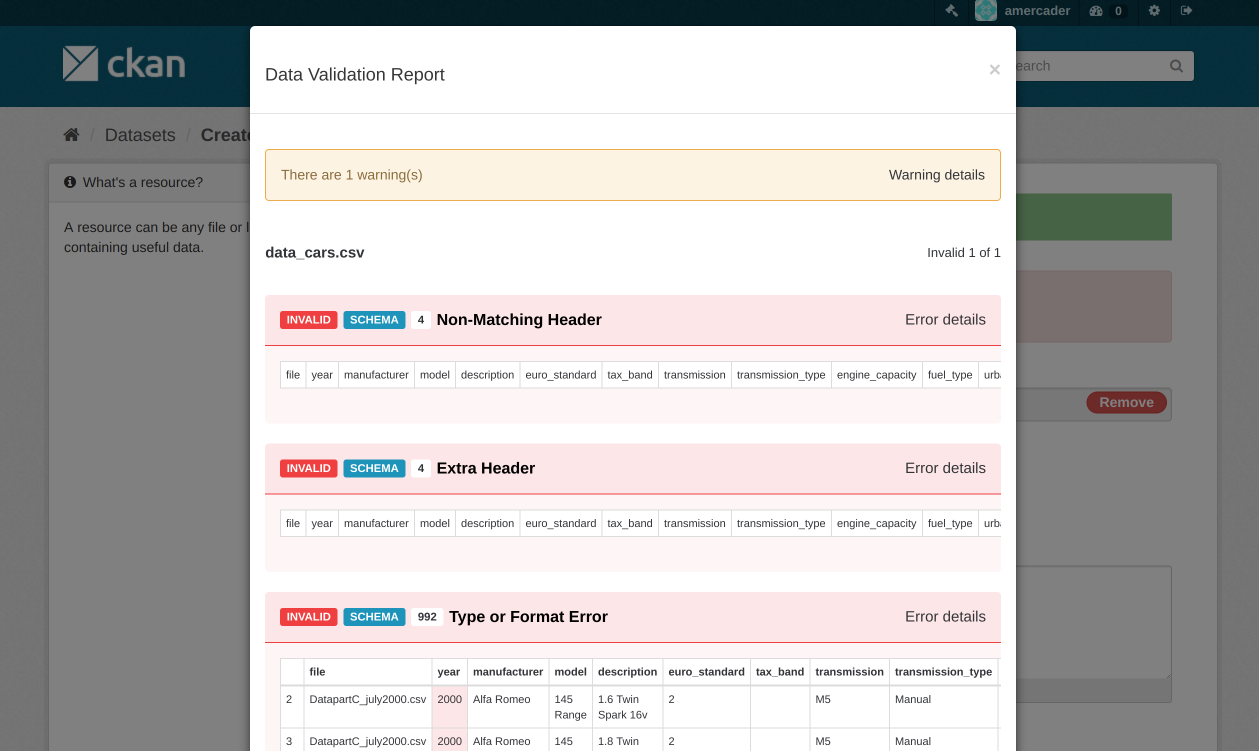
data validation on upload or linking to a new tabular file on CKAN
The extension adds functionality to provide a schema (opens new window) for the data that describes the expected fields and types as well as other constraints, allowing to perform validation on the actual contents of the data. Additionally the schema is also stored with the resource metadata, so it can be displayed in the UI or accessed via the API.
The extension also provides some utility commands for CKAN maintainers, including the generation of reports (opens new window) showing the number of valid and invalid tabular files, a breakdown of the error types and links to the individual resources. This gives maintainers a snapshot of the general quality of the data hosted in their CKAN instance at any given moment in time.
As mentioned before, we field tested the validation extension on the Western Pennsylvania Regional Data Center (WPRDC). At the moment of the import the portal hosted 258 datasets. Out of these, 221 datasets had tabular resources, totalling 626 files (mainly CSV and XLSX files). Taking into account that we only performed the default validation that only includes structural checks (ie not schema-based ones) these are the results:
466 resources - validation success
156 resources - validation failure
4 resources - validation error
The errors found are due to current limitations in the validation extension with large files.
Here’s a breakdown of the formats:
| Valid resources | Invalid / Errored resources | |
|---|---|---|
| CSV | 443 | 64 |
| XLSX | 21 | 57 |
| XLS | 2 | 39 |
And of the error types (more information about each error type can be found in the Data Quality Specification (opens new window)):
| Type of Error | Error Count |
|---|---|
| Blank row | 19654 |
| Duplicate row | 810 |
| Blank header | 299 |
| Duplicate header | 270 |
| Source error | 30 |
| Extra value | 11 |
| Format error | 9 |
| HTTP error | 2 |
| Missing value | 1 |
The highest number of errors are obviously caused by blank and duplicate rows. These are generally caused by Excel adding extra rows at the end of the file or by publishers formatting the files for human rather than machine consumption. Examples of this include adding a title in the first cell (like in this case: portal page (opens new window) | file (opens new window)) or even more complex layouts (portal page (opens new window) | file (opens new window)), with logos and links. Blank and duplicate header errors like on this case (portal page (opens new window) | file (opens new window)) are also normally caused by Excel storing extra empty columns (and something that can not be noticed directly from Excel).
These errors are easy to spot and fix manually once the file has been opened for inspection but this is still an extra step that data consumers need to perform before using the data on their own processes. It is also true that they are errors that could be easily fixed automatically as part of a pre-process of data cleanup before publication. Perhaps this is something that could be developed in the validation extension in the future.
Other less common errors include Source errors, which include errors that prevented the file from being read by goodtables, like encoding issues or HTTP responses or HTML files incorrectly being marked as Excel files (like in this case: portal page (opens new window) | file (opens new window)). Extra value errors are generally caused by not properly quoting fields that contain commas, thus breaking the parser (example: portal page (opens new window) | file (opens new window)).
Format errors are caused by labelling incorrectly the format of the hosted file, for instance CSV when it links to an Excel file (portal page (opens new window) | file (opens new window)), CSV linking to HTML (portal page (opens new window) | file (opens new window)) or XLS linking to XLSX (portal page (opens new window) | file (opens new window)). These are all easily fixed at the metadata level.
Finally HTTP errors just show that the linked file hosted elsewhere does not exist or has been moved.
Again, it is important to stress that the checks performed are just basic and structural checks (opens new window) that affect the general availability of the file and its general structure. The addition of standardized schemas would allow for a more thorough and precise validation, checking the data contents and ensuring that this is what was expected.
Also it is interesting to note that WPRDC has the excellent good practice of publishing data dictionaries describing the contents of the data files. These are generally published in CSV format and they themselves can present validation errors as well. As we saw before, using the validation extension we can assign a schema defined in the Table Schema spec to a resource. This will be used during the validation, but the information could also be used to render it nicely on the UI or export it consistently as a CSV or PDF file.
All the generated reports can be further analyzed using the output files stored in this repository (opens new window).
Additionally, to help browse the validation reports created from the WPRDC site we have set up a demo site that mirrors the datasets, organizations and groups hosted there (at the time we did the import).
All tabular resources have the validation report attached, that can be accessed clicking on the data valid / invalid badges.
# Next Steps
# Areas for further work
The validation extension for CKAN currently provides a very basic workflow for validation at creation and update time: basically if the validation fails in any way you are not allowed to create or edit the dataset. Maintainers can define a set of default validation options to make it more permissive but even so some publishers probably wouldn’t want to enforce all validation checks before allowing the creation of a dataset, or just apply validation to datasets from a particular organization or type. Of course the underlying API (opens new window) is available for extension developers to implement these workflows, but the validation extension itself could provide some of them.
The user interface for defining the validation options can definitely be improved, and we are planning to integrate a Schema Creator (opens new window) to make easier for publishers to describe their data with a schema based on the actual fields on the file. If the resource has a schema assigned, this information can be presented nicely on the UI to the users and exported in different formats.
The validation extension is a first iteration to demonstrate the capabilities of integrating data validation directly into CKAN, but we are keen to know about different ways in which this could be expanded or integrated in other workflows, so any feedback or thoughts is appreciated.
# Additional Resources
Check the full documentation (opens new window) for ckanext-validation, covering all details on how to install it and configure it, features and available API
Source material:
Western Pennsylvania Regional Data Center Github repository (opens new window)