
Zegami

Zegami (opens new window) makes information more visual and accessible, enabling intuitive exploration, search and discovery of large data sets. Zegami combines the power of machine learning and human pattern recognition to reveal hidden insights and new perspectives.
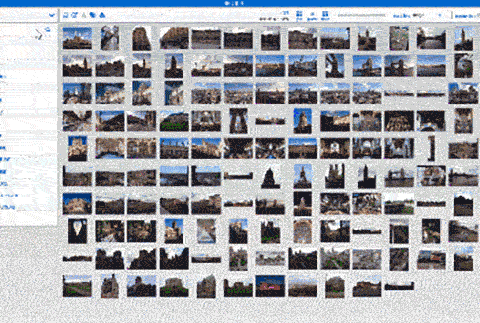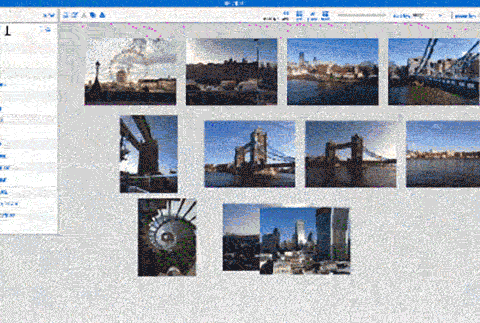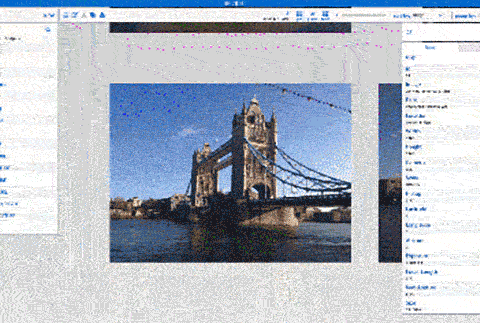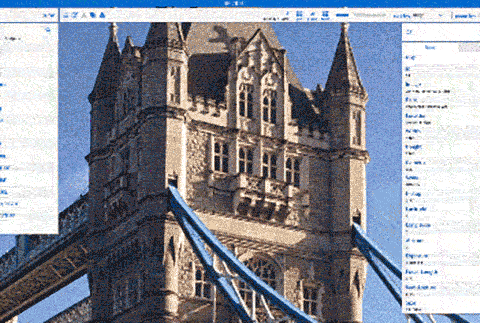
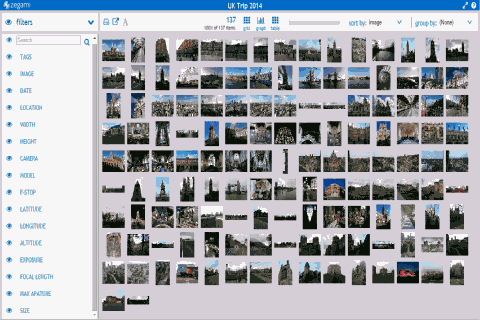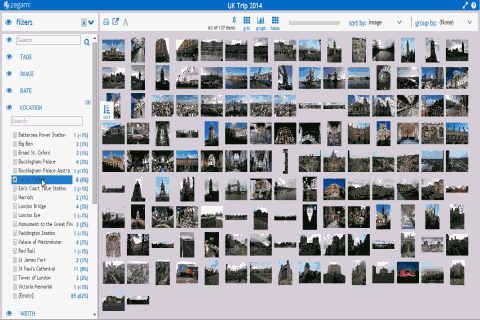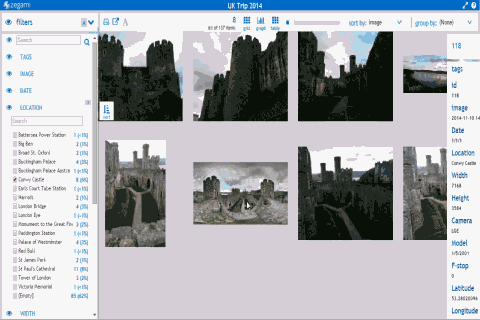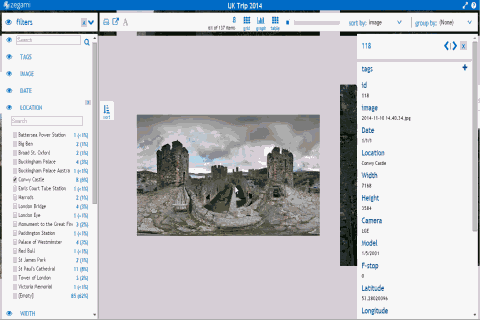
image search on Zegami
It provides a more powerful tool for visual data than what’s possible with spreadsheets or typical business intelligence tools. By presenting data within a single field of view, Zegami enables users to easily discover patterns and correlations. Facilitating new insights and discoveries that would otherwise not be possible.
metadata search on Zegami
For Zegami to shine, our users need to be able to easily import their data so they can get actionable insight with minimal fuss. In building an analytics platform we face the unique challenge of having to support a wide variety of data sources and formats. The challenge is compounded by the fact that the data we deal with is rarely clean.
At the onset, we also faced the challenge of how best to store and transmit data between our components and micro-services. In addition to an open, extensible and simple yet powerful data format, we wanted one that can preserve data types and formatting, and be parsed by all the client applications we use, which includes server-side applications, web clients and visualisation frameworks.
We first heard about messytables[1] and of the data protocols site (currently Frictionless Data Specifications[2]) through a lightning talk at EuroSciPy 2015. This meant when we searched for various things around jsontableschema (now tableschema[3]), we landed on the Frictionless Data project.
We are currently using the specifications in the following ways:
- We use tabulator.Stream[4] to parse data on our back end.
- We use schema infer from tableschema-py[5] to store an extended json table schema to represent data structures in our system. We are also developing custom json parsers using json paths and the ijson library
In the coming days, We plan on using
- datapackage-pipelines[6] as a spec for the way we treat joins and multi-step data operations in our system
- tabulator in a polyglot persistence scenario[7] - storing data in both storage buckets and either elasticsearch[8] or another column store like druid.io (opens new window).
Moving forward it would be interesting to see tableschema and tabulator as a communication protocol over websockets. This would allow for a really smooth experience when using handsontable[9] spreadsheets with a datapackage of some kind. A socket-to-socket version of datapackage-pipelines which runs on container orchestration systems would also be interesting. There are few protocols similar to datapackage-pipelines, such as Dask[10] which, although similar, is not serialisable and therefor unsuitable for applications where front end communication is necessary or where the pipelines need to be used by non-coders.
We are also keen to know more about repositories around the world that use datapackages[11] so that we can import the data and show users and owners of those repositories the benefits of browsing and visualising data in Zegami.
In terms of other potential use cases, it would be useful to create a python-based alternative to the dreamfactory API server[12]. wqio (opens new window) is one example, but it is quite hard to use and a lighter version would be great. Perhaps CKAN[13] datastore could be licensed in a more open way?
In terms of the next steps for us, we are currently working on a SaaS implementation of Zegami which will dramatically reduce the effort required in order to start working with Zegami. We are then planning on developing a series of APIs so developers can create their own data transformation pipelines. One of our developers, Andrew Stretton, will be running Frictionless Data sessions at PyData London[14] on Tuesday, October 3 and PyCon UK[15] on Friday, October 27.
Library for parsing messy tabular data: https://github.com/okfn/messytables (opens new window) ↩︎
Frictionless Data Specifications: specs (opens new window) ↩︎
Table Schema: https://specs.frictionlessdata.io/table-schema (opens new window) ↩︎
Tabulator: library for reading and writing tabular data https://github.com/frictionlessdata/tabulator-py (opens new window) ↩︎
Table Schema Python Library: https://github.com/frictionlessdata/tableschema-py (opens new window) ↩︎
Data Package Pipelines: https://github.com/frictionlessdata/datapackage-pipelines (opens new window) ↩︎
Polyglot Persistence: https://en.wikipedia.org/wiki/Polyglot_persistence (opens new window) ↩︎
Elastic Search: https://www.elastic.co/products/elasticsearch (opens new window) ↩︎
Handsontable: Javascript spreadsheet component for web apps: https://handsontable.com (opens new window) ↩︎
Dask Custom Graphs: http://dask.pydata.org/en/latest/custom-graphs.html (opens new window) ↩︎
Data Packages: https://specs.frictionlessdata.io/data-package (opens new window) ↩︎
Dream Factory: https://www.dreamfactory.com/ (opens new window) ↩︎
CKAN: Open Source Data Portal Platform: https://ckan.org (opens new window) ↩︎
PyData London, October 2017 Meetup: https://www.meetup.com/PyData-London-Meetup/events/243584161/ (opens new window) ↩︎
PyCon UK 2017 Schedule: http://2017.pyconuk.org/schedule/ (opens new window) ↩︎