
Dataship

Dataship (opens new window) is a way to share data and analysis, from simple charts to complex machine learning, with anyone in the world easily and for free. It allows you to create notebooks that hold and deliver your data, as well as text, images and inline scripts for doing analysis and visualization. The people you share it with can read, execute and even edit a copy of your notebook and publish the remixed version as a fork.
One of the main challenges we face with data is that it’s hard to share it with others. Tools like Jupyter (iPython notebook)[1] make it much easier and more affordable to do analysis (with the help of open source projects like numpy[2] and pandas[3]). What they don’t do is allow you to cheaply and easily share that with the world. If it were as easy to share data and analysis as it is to share pictures of your breakfast, the world would be a more enlightened place. Dataship is helping to build that world.
Every notebook on Dataship is also a Data Package[4]. Like other Data Packages it can be downloaded, along with its data, just by giving its URL to software like data-cli[5]. Additionally, working with existing Data Packages is easy. Just as you can fork other notebooks, you can also fork existing Data Packages, even when they’re located somewhere else, like GitHub.
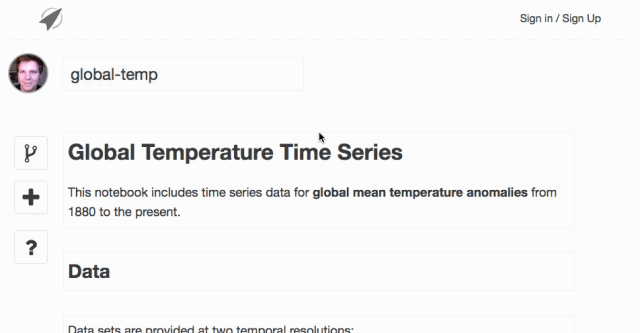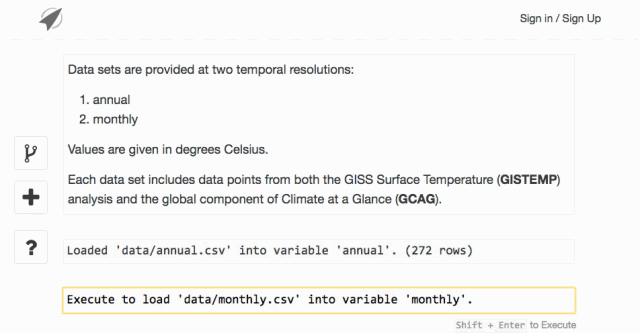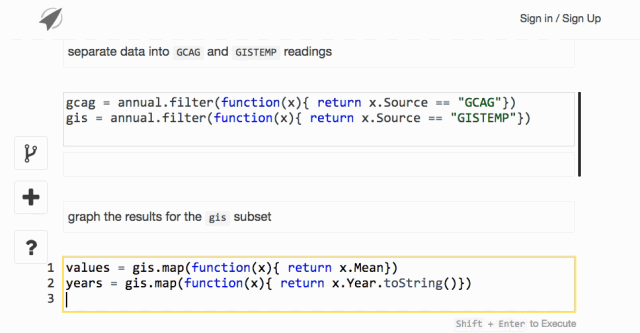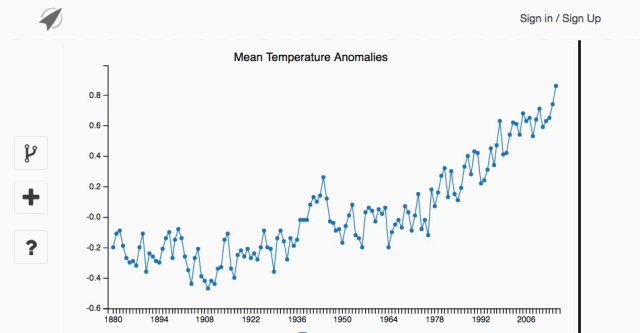
Dataship in action
Every cell in a notebook is represented by a resource entry[6] in an underlying Data Package. This also allows for interesting possibilities. One of these is executable Data Packages. Since the code is included inline and its dependencies are explicit and bounded, very simple software could be written to execute a Data Package-based notebook from the command line, printing the results to the console and writing images to the current directory.
It would be useful to have a JavaScript version of some of the functionality in goodtables[7] available for use, specifically header detection in parsed csv contents (output of PapaParse), as well as an option in dpm to not put things in a ‘datapackages’ folder, as I rarely need this when downloading a dataset.
dpm, mentioned above, is now deprecated. Check out DataHub’s data-cli (opens new window)
My next task will be building and integrating the machine learning and neural network components into Dataship. After that I’ll be focusing on features that allow organizations to store private encrypted data, in addition to the default public storage. The focus of the platform will always be open data, but hosting closed data sources will allow us to nudge people towards sharing, when it makes sense.
As for additional use cases, the volume of personal data is growing exponentially- from medical data to internet activity and media consumption. These are just a few existing examples. The rise of the Internet of Things will only accelerate this. People are also beginning to see the value in controlling their data themselves. Providing mechanisms for doing this will likely become important over the next ten years.
Jupyter Notebook: http://jupyter.org/ (opens new window) ↩︎
NumPy: Python package for scientific computing: http://www.numpy.org (opens new window) ↩︎
Pandas: Python package for data analysis: http://pandas.pydata.org/ (opens new window) ↩︎
Data Packages: ↩︎
DataHub’s data commandline tool: https://github.com/datahq/data-cli (opens new window) ↩︎
Data Package Resource: https://specs.frictionlessdata.io/data-package/#resource-information (opens new window) ↩︎
goodtables: http://try.goodtables.io (opens new window) ↩︎